
How Semantic Segmentation Works
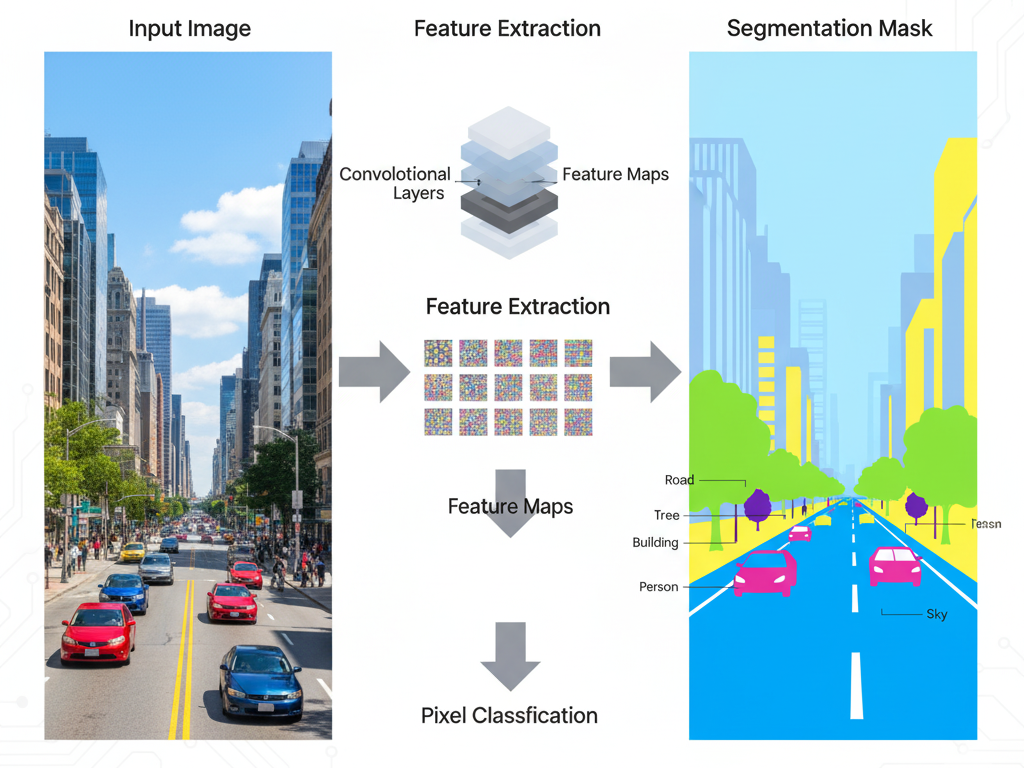
Data Preparation: The process begins with annotated datasets where every pixel is labeled with its class (e.g., sky, car, road).
Feature Extraction: Deep neural networks (like CNNs or Vision Transformers) extract spatial and contextual features from the image.
Pixel Classification: Each pixel is classified based on its extracted features and surrounding context.
Upsampling / Decoding: The network reconstructs pixel-level predictions using upsampling layers (e.g., in U-Net, SegNet, or DeepLab architectures).
Mask Generation: A color-coded segmentation mask is generated, overlaying class labels onto the original image.
Post-Processing: Techniques like Conditional Random Fields (CRFs) or edge refinement are used to sharpen object boundaries.
Model Optimization: The model is fine-tuned using metrics like Intersection over Union (IoU) and Pixel Accuracy to improve segmentation quality.
Types of Segmentation
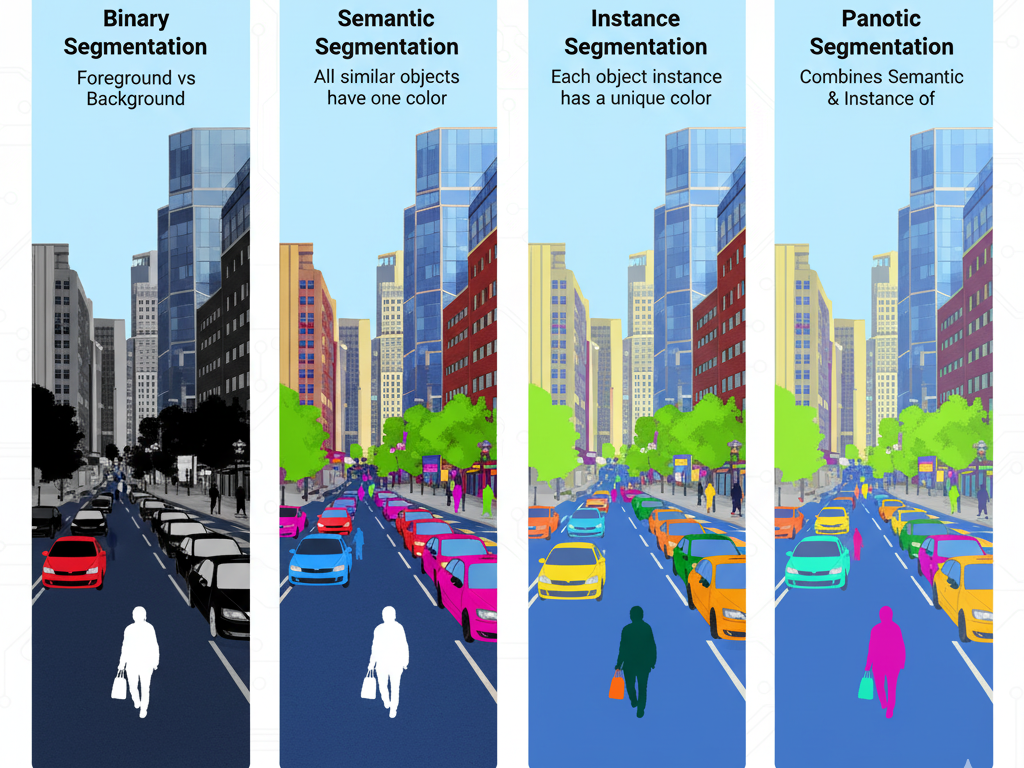
Semantic Segmentation:
- Assigns a class label to each pixel.
Instance Segmentation:
- Identifies each object instance separately within the same class.
Panoptic Segmentation:
- A hybrid of semantic and instance segmentation.
Binary Segmentation:
- Simplest form — classifies pixels into two categories (e.g., foreground vs background).
3D Segmentation:
- Extends semantic segmentation into 3D environments (e.g., LiDAR point clouds).
Applications
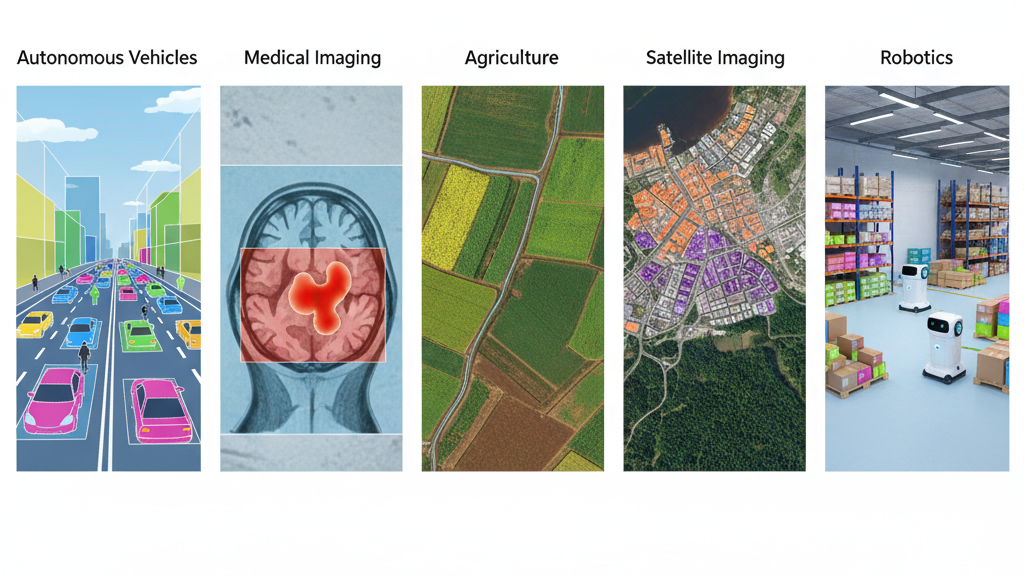
Autonomous Vehicles: Understanding roads, lanes, pedestrians, and obstacles.
Medical Imaging: Identifying tissues, tumors, or organs at the pixel level.
Agriculture: Segmenting crops, soil, and weeds for precision farming.
Aerial & Satellite Imagery: Land-use classification, forest monitoring, and urban mapping.
Robotics: Scene understanding for navigation and manipulation.
AR/VR: Separating background and foreground objects for immersive environments.