
What is Data Processing?

Data processing is the structured sequence of steps used to collect, clean, transform, organize, and prepare raw data into a usable and meaningful format. This process ensures that information is accurate, consistent, and ready for analysis or machine learning applications. By converting raw data into actionable insights, data processing becomes essential for AI model training, business intelligence, and informed decision-making. It enhances the reliability, efficiency, and value of data, enabling organizations to leverage information effectively for strategic outcomes.
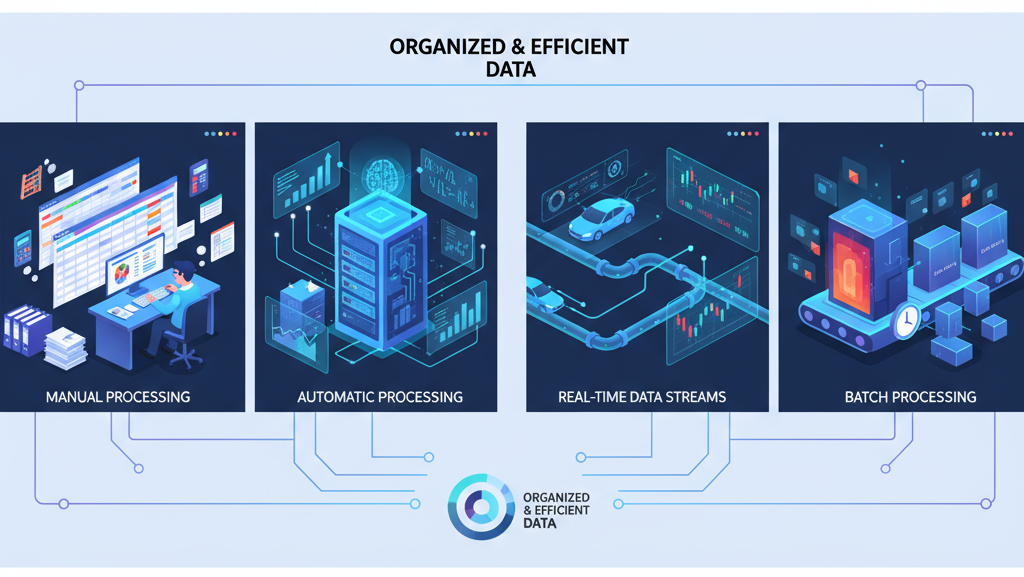
Types of Data Processing
Data processing can be categorized into several types. Manual data processing involves human effort to clean, organize, or input data, such as updating spreadsheets, and is suitable for small-scale tasks despite being time-consuming and error-prone. Automatic (electronic) data processing uses computers, algorithms, and pipelines to handle large datasets, enable real-time analytics, and support AI model training. Real-time processing handles data instantly, crucial for applications like self-driving cars, financial trading, and fraud detection. Batch processing manages large data volumes at once, commonly used in data warehousing, billing, and research.
Key Steps in the Data Processing Workflow
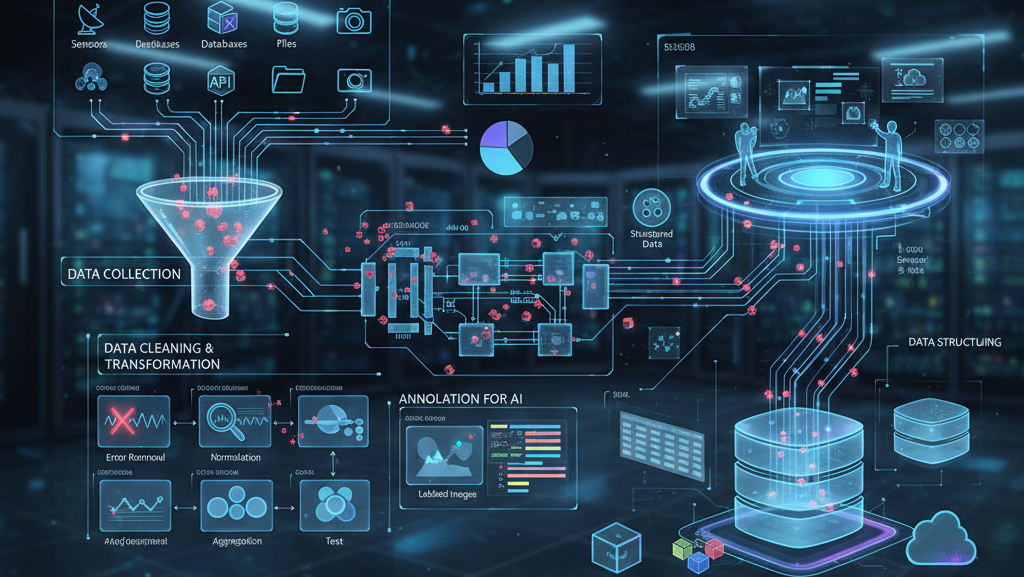
Data processing begins with data collection from sources like sensors, databases, APIs, files, cameras, or user inputs, which may be structured, semi-structured, or unstructured. The data is then cleaned to remove errors, duplicates, and inconsistencies, and transformed through normalization, encoding, or aggregation. For AI applications, data annotation labels the data, while structuring organizes it into databases or tables for easy retrieval and analysis, followed by validation to ensure quality and accuracy.
A futuristic data management scene showing processed data being stored in SQL/NoSQL databases, cloud storage, and data lakes with secure access controls and backups. Visualize dashboards, machine learning models, and real-time applications using the data. Include graphs, charts, AI icons, and glowing connections to convey actionable insights and business intelligence emerging from structured, validated, and managed data.
